


GPT 4.5 Released, here are the Benchmarks: A Simple Breakdown
The benchmarks in this table provide a comparative evaluation of three AI models—GPT-4.5, GPT-4o, and OpenAI o3-mini (high)—across various tasks relevant to science, math, multilingual understanding.

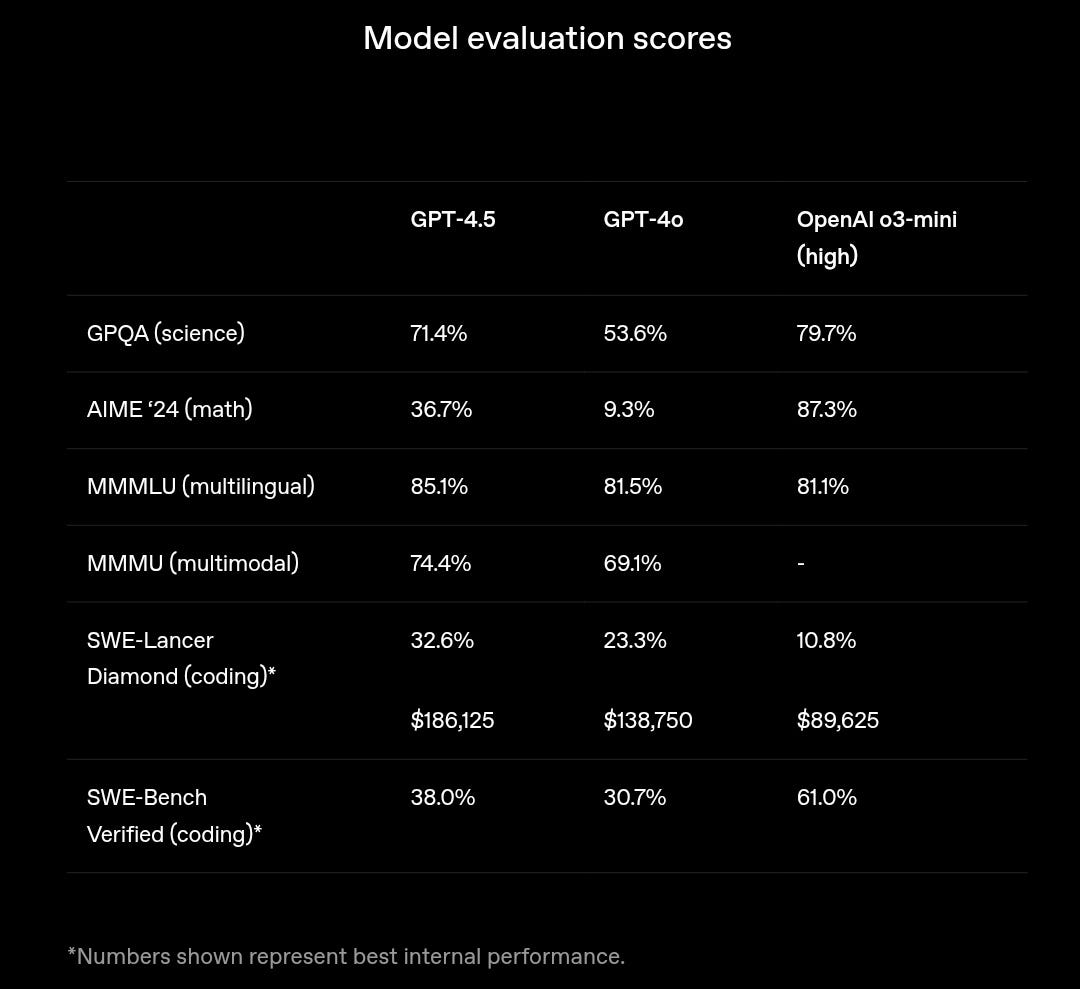
Artificial Intelligence (AI) tools are becoming essential to solve problems, automate tasks, and deliver better results for clients. But not all AI models perform equally well in every area. The benchmarks in this table provide a comparative evaluation of three AI models—GPT-4.5, GPT-4o, and OpenAI o3-mini (high)—across various tasks relevant to science, math, multilingual understanding, multimodal capabilities, and coding. For consultants in the industry, this information is valuable for understanding the strengths and weaknesses of these models, enabling better decision-making when selecting AI tools for specific applications.
Why These Benchmarks Matter
AI models are increasingly critical in solving complex business problems, automating workflows, and enhancing productivity. However, not all AI models perform equally well across different tasks. This benchmark comparison helps identify which model is best suited for specific needs like scientific reasoning, mathematical problem-solving, multilingual tasks, multimodal analysis (e.g., combining text and images), or coding.
Key Insights from the Benchmarks
The table evaluates five major areas of performance:
Scientific Reasoning (GPQA)
Mathematical Problem-Solving (AIME '24)
Multilingual Understanding (MMMLU)
Multimodal Capabilities (MMMU)
Coding Proficiency (SWE-Lancer and SWE-Bench)
Each area highlights how the models perform under specific conditions, to help understand where these tools excel or fall short.
1. Scientific Reasoning (GPQA)
What it measures: The ability to answer graduate-level science questions. GPQA measures how well a model handles scientific questions, such as those in biology, physics, or chemistry. This is crucial if working on projects in healthcare, energy, or technology sectors where scientific accuracy is key.
Performance:
OpenAI o3-mini leads with 79.7%, followed by GPT-4.5 at 71.4%, and GPT-4o at 53.6%.
Takeaway: If your work involves industries like healthcare, engineering, or any technical field where deep scientific knowledge is needed, OpenAI o3-mini is your best bet because it answers science questions most accurately.
2. Mathematical Problem-Solving (AIME '24)
What it measures: Advanced math problem-solving ability. AIME ‘24 evaluates a model’s ability to solve advanced math problems, similar to those in high school or college competitions. This is relevant if working on financial modeling, optimization, or engineering projects.
Performance:
OpenAI o3-mini dominates with 87.3%, far ahead of GPT-4.5 (36.7%) and GPT-4o (9.3%).
Takeaway: For consultants working in finance, data analytics, or any field that needs strong math problem-solving, OpenAI o3-mini is the clear winner here.
3. Multilingual Understanding (MMMLU)
What it measures: Proficiency in understanding and responding in multiple languages.
Performance:
GPT-4.5 leads at 85.1%, followed closely by GPT-4o at 81.5% and OpenAI o3-mini at 81.1%.
Takeaway: If you’re working with global clients or need to handle multiple languages in your projects, all three models perform well here, but GPT-4.5 has a slight edge.
4. Multimodal Capabilities (MMMU)
What it measures: The ability to process and integrate information from multiple modes like text and images. MMMU assesses a model’s ability to handle both text and visual data, such as interpreting charts, graphs, or images alongside written content.
Performance:
GPT-4.5 scores highest at 74.4%, followed by GPT-4o at 69.1%. Data for OpenAI o3-mini is unavailable.
Consultant Takeaway: For consultants working in marketing, design, or any field where text and visuals need to be analyzed together, GPT-4.5 is the top choice.
5. Coding Proficiency (SWE-Lancer and SWE-Bench)
SWE-Lancer Diamond:
What it measures: Coding skills for competitive programming tasks.
Performance:
GPT-4.5 earns $186,125 in simulated earnings, outperforming GPT-4o $138,750 and OpenAI o3-mini $89,625.
SWE-Bench Verified:
What it measures: General coding capabilities.
Performance:
OpenAI o3-mini leads with 61%, followed by GPT-4.5 at 38% and GPT-4o at 30.7%.
Consultant Takeaway: For highly specialized coding challenges (e.g., software development), GPT-4.5 is better suited for competitive programming tasks (SWE-Lancer). However, for general coding needs like automation scripts or debugging (SWE-Bench), OpenAI o3-mini performs better.
Actionable Insights for Consultants
Here’s how consultants can use this data:
Match AI Strengths to Business Needs:
Use OpenAI o3-mini for math-heavy industries like finance or engineering.
Leverage GPT-4.5 for multilingual client projects or multimodal analysis.
Opt for OpenAI o3-mini for general-purpose coding automation.
Optimize Resource Allocation:
If budget constraints exist but high performance is needed in specific areas like science or math, prioritize tools like OpenAI o3-mini.
For balanced performance across diverse tasks, consider GPT-4.5.
Future-Proof Decision-Making:
As AI evolves rapidly, focus on models excelling in areas critical to your consulting niche to stay competitive.
Conclusion
This benchmark comparison simplifies the decision-making process by highlighting the strengths of each model across key domains like science, math, language understanding, multimodal analysis, and coding proficiency. By aligning these capabilities with your business needs—whether it’s global operations, technical problem-solving, or software development—you can select the most effective AI tool to enhance productivity and deliver better outcomes for clients.